Serijal tekstova: Zajedno naučimo Python (7. dio) – N-torke i rječnici
Pozdrav svima i dobrodošli u sedmi Python tutorial. Do sada smo obradili već dosta toga, no danas krećemo korak dalje. Prošli put smo zakoračili u, recimo tako, drugi dio ovog serijala gdje smo za početak obradili liste. Liste su bile relativno novi pojam koji sa sobom nosi nove mogućnosti i samim time u nama budi dodatnu kreativnost. Način da ih prepoznamo su uglate zagrade. Međutim, ako ste se prošli puta zapitali što je s ostalim zagradama, odgovor leži u današnjem tutorialu.
Python je u svojoj sintaksi upotrijebio sve tri vrste zagrada i to na sljedeći način; za n-torke se koriste (), za liste [], dok za rječnike {}. Pošto smo prošli puta govorili o listama, za danas su nam ostale n-torke i rječnici.
Krenimo prvo s n-torkama, a kasnije ćemo prijeći na rječnike. N-torka (engl. tuple) je tip podatka vrlo sličan listi, ali s određenim razlikama. Za početak, kako bismo zadali n-torku, koristimo sljedeću sintaksu:
ntorka = (1, 2, 4)
Kao što vidite, kod n-torki se koriste okrugle zagrade, dok smo kod lista koristili uglate. Sljedeća važna stvar je da kada jednom napravimo n-torku, njen sadržaj se ne može mijenjati. Pod tim mislimo na dodavanje sadržaja u n-torku, brisanje sadržaja iz n-torke odnosno zamjena elemenata unutar nje. Naravno, cijelu n-torku je moguće brisati i to pomoću funkcije del(). Isto tako, moguće je iz više n-torki napraviti neku novu n-torku, a to možete vidjeti na sljedećoj slici.
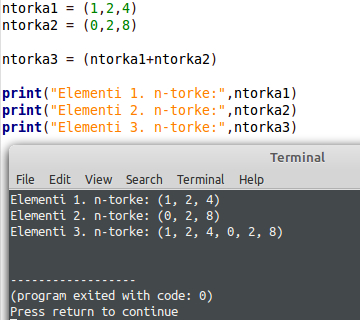
Što se pristupa tiče, elementima n-torke pristupamo isto kao i kod lista, pomoću indeksa. Stoga, ako želimo pristupiti prvom odnosno trećem elementu, pišemo:
ntorka[0]
ntorka[2]
Vidite da se pri pisanju indeksa i dalje koriste uglate zagrade. Imajte to na umu!
Iako nam n-torke izgledaju prilično limitirane, one imaju raznih svrha. Za neke smo ih mi već koristili, a primjer toga je bio ispis više elemenata;
a = 5
b = 10
c = a+b
print(“Zbroj {} i {} je {}”.format(a, b, c))
Upravo ovo što se nalazi unutar zagrada .format() metode je n-torka. Nije moguće mijenjati njen poredak, modificirati ili na bilo koji drugi način utjecati na nju. Ovdje vidimo prednost korištenja n-torke. Isto tako, n-torke možemo svakako koristiti pri iteracijama, tako da svakako iskoristite i tu mogućnost:
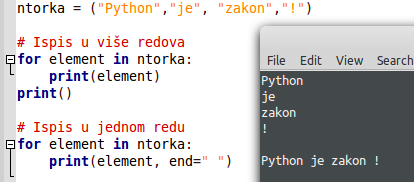
Ovdje treba ipak napomenuti jednu stvar. Mnogi se znaju zabuniti, pa čak i pogriješiti pri pisanju n-torke sa samo jednim elementom. To se radi na sljedeći način:
ntorka = (“auto”,)
Kao što vidite, unutar zagrada je napisan element, odnosno string “auto”, ali ono što je važno je ZAREZ nakon toga. Bez zareza to neće biti n-torka, već obični tip podatka (ovisno što ćemo upisati). Stoga, ako radite n-torku od jednog elementa, svakako pripazite na zarez.
N-torke u Pythonu ne izgledaju previše “moćno”, ali se koriste češće nego mislite. Kao jedna od glavnih koristi jest vraćanje više vrijednosti iz funkcija (biti će obrađeno u kasnijim tutorialima). Isto tako, vrlo je lako i jednostavno uz pomoć n-torki izračunavati razne matematičke zadatke i funkcije, što zapravo u većini slučajeva i sam program u “pozadini” radi.
Za sam kraj ostavio sam neke funkcije koje se najčešće mogu koristiti pri radu s n-torkama:
len(ime_ntorke)
Prva od njih je funkcija za dužinu. Unutar zagrade se piše ime n-torke. Zapravo, sve je isto kao i kod liste.
min(ime_ntorke)
Funkcija za ispis najmanjeg elementa n-torke.
max(ime_ntorke)
Funkcija za ispis najvećeg elementa n-torke.
Funkcije min() i max() vrijede i za liste, međutim, njih prošli puta nisam naveo čisto iz razloga da pokušate zadatak riješiti pomoću sortiranja (malo više kreativnosti 😛 ).
tuple(ime_liste)
Ova funkcija pretvara listu u n-torku. Isto tako, postoji funkcija list(), koja pretvara n-torku u listu.
Nakon što smo obradili n-torke, vrijeme je za rječnike. Iako je dio o n-torkama relativno kratak, nadoknadit ćemo to s rječnicima. 🙂
Rječnici (engl. dictionary) su tipovi podataka, koji imaju oblik ključ:vrijednost(i). Rječnik pokušajte zamisliti kao tablicu, gdje se u prvom stupcu nalazi ključ, recimo OIB, a u ostalim se stupcima tog istog reda nalazi vrijednost(i) koji imaju veze s tim ključem (ime, prezime, datum rođenja…).
Prazni rječnik zapisujemo:
rjecnik = {}
Općenito, rječnik uvijek ima vitičaste zagrade i prema tome ga razlikujemo od n-torki ili lista. Ako želimo napraviti rječnik s ključevima i vrijednostima, to radimo na sljedeći način:
rjecnik = {1001:”Ana”, 2912:”Ivan”}
Elementi rječnika su odvojeni zarezom, tako da u ovom slučaju imamo dva elementa, prvi s ključem 1001 te vrijednošću “Ana”, dok je ključ drugog elementa 2912, a vrijednost mu je “Ivan”. Ako bismo željeli pristupiti drugom elementu, pišemo:
rjecnik[1001]
Ovdje treba naglasiti da se elementima rječnika NE PRISTUPA preko indeksa, već SAMO preko ključa. Ako upišemo ključ koji se ne nalazi u rječniku, to će se prikazati u obliku greške. Također, kao napomena; ključ može biti tipa integer, float ili string.
Ključ kao što vidite, ima striktno propisano što može biti. S druge strane, kao vrijednost pojedinog elementa rječnika može biti gotovo bilo što (integer, string, float, lista, n-torka…).
Ako krenemo malo dalje i zamislimo zadatak gdje unosimo ključ, a program nam treba izbaciti vrijednosti, vidimo problem. Ako unesemo ključ koji se ne nalazi u rječniku, program će javiti grešku. Kako se to nebi događalo, postoji mogućnost provjere da li u rječniku postoji, odnosno ne postoji određeni ključ. Ako želimo provjeriti da li određeni ključ postoji u rječniku, pišemo sljedeće:
if kljuc in rjecnik:
u suprotnom, dok tražimo da li je određeni ključ “slobodan” tj. nije u rječniku, pišemo:
if not kljuc in rjecnik:
Da sad previše ne brzamo, prvo ću objasniti o čemu se radi. Ako želite ispisati neku vrijednost iz rječnika, a niste sigurni da li je ta vrijednost u rječniku, najlakše je napisati jednu if selekciju koja to provjerava. Prvi red koji sam napisao (if kljuc in rjecnik) prolazi kroz rječnik i traži ključ s tom vrijednošću. Ako ga nađe, vraća vrijednost True i ulazi se u selekciju if.
Sada zamislimo situaciju da ispitujemo da li neki ključ ne postoji u rječniku, jer ako taj ključ nije u rječniku, možemo pod taj ključ napisati neke vrijednosti. Pa tako opet koristimo if selekciju, međutim, sad je važan not koji negira da postoji taj ključ u rječniku. Ako dobijemo vrijednost True, znači da tog ključa nema i slobodni smo uz taj ključ zapisati nove vrijednosti. Razlog tome je taj da ako taj ključ postoji, novim sadržajem bismo prebrisali stari sadržaj. Primjere toga možete vidjeti na sljedećim slikama:
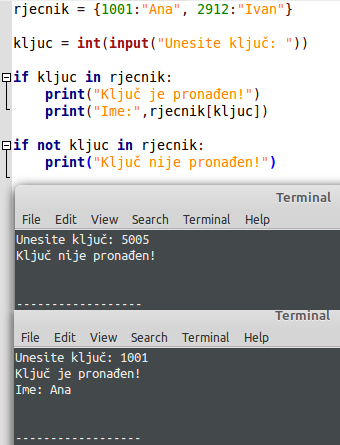
Ovim smo zapravo pokrili mogućnost greške pri izvedbi programa, odnosno, brisanje starog sadržaja unosom novog. To je bila uvertira za unos novih elemenata u rječnik. Ako želimo dodati neku novu vrijednost u rječnik, potrebno je kraj imena rječnika u uglatim zagradama napisati ključ, nakon toga znak pridruživanja te vrijednost koju pridružujemo. Kraće zapisano:
rjecnik[kljuc] = vrijednost
Ako želimo promijeniti vrijednosti koje se već nalaze u rječniku, njima pristupamo isto preko ključa na potpuno isti način kao i pri upisu novog elementa. Naravno, u ovom slučaju ključ već mora postojati u rječniku, dok pri unosu novog elementa ključ ne smije biti u rječniku sve do njegovog unosa.
Što se brisanja elemenata tiče, opet se sve radi preko ključa 😀 Funkcija za brisanje je del():
del(rjecnik[kljuc])
Ako želimo obrisati cijeli rječnik, koristimo metodu .clear(), a to u praksi izgleda ovako:
rjecnik.clear()
Ono što nam dalje slijedi je priprema za završni zadatak. Naime, dosad smo samo tražili da li se u rječniku nalazi odnosno ne nalazi određen ključ. Slijedi ispis vrijednosti iz rječnika. Recimo da imamo sljedeći rječnik:
vocarna = {1001:”jabuka”, 1002:”kruška”, 1003:”jagoda”, 1011:”kivi”, 1043:”ananas”}
Ono što želimo je ispisati šifre i kraj njih ime voća. Prvo što trebamo znati je, ako iz rječnika želimo pročitati podatke, trebamo jednu varijablu za ključ (šifru) i drugu za vrijednost (ime voća). Osim toga, treba nam metoda .items() koja nam vraća ključ i vrijednost elementa. Pošto ovdje imamo više elemenata, koristit ćemo for iteraciju i naravno, print() funkciju za ispis. To bi trebalo izgledati ovako:
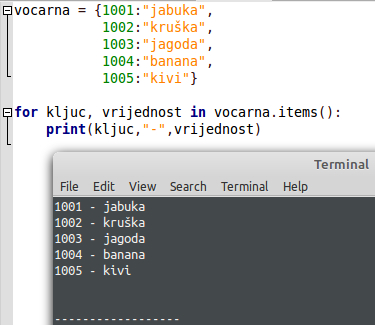
Također, želio bih napomenuti da u slučaju ako imamo vrijednost kao listu, tada moramo paziti pri ispisu. Jer ako sve ostavimo kao na prijašnjoj slici, dobit ćemo ispisanu listu. Stoga elementima liste još dodatno pristupamo preko indeksa. Naravno, to ćemo sve provježbati kroz posljednji zadatak.
Zadatak koji slijedi je da napravimo program koji će provjeravati prema OIB-u da li je osoba upisana na fakultet.
Prvo će nam se ispisati tablica s upisanim studentima, odnosno, OIB-om i njihovim imenima i prezimenima. Ako ćemo unijeti OIB iz tablice, ispisat će se svi podaci studenta. Međutim, ako uneseni OIB-a ne odgovara ni jednom OIB-u iz tablice, program će zatražiti unos podataka za studenta s tim OIB-om. Nakon toga će se ispisati nova tablica koja sadrži i unesenog studenta.
Za početak nam je potreban rječnik koji sadrži neke određene podatke, u ovom slučaju; OIB, ime, prezime, status studenta, godinu upisa i godinu studija:

NAPOMENA: OIB pišemo kao string jer želimo da nam broj bude i s nulama na početku. Također, u ovom programu nećemo vršiti provjeru da li je OIB u potpunosti točno unesen.
Nakon rječnika, potreban nam je ispis istog. Za to koristimo već poznati način ispisa od prije, međutim, sada unutar same for iteracije, odnosno ispisa pojedinog reda baratamo i s indeksima liste kako bismo dobili sve lijepo ispisano u tablici, a ne samo listu u cjelini.
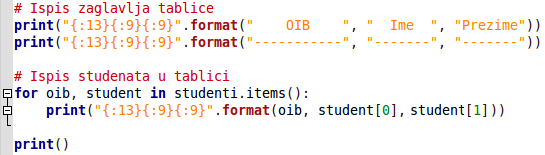
Kako bismo mogli omogućiti unos OIB-a, potrebna nam je nova varijabla u koju ćemo spremati vrijednost ključa odnosno OIB. S druge strane, ako će se unijeti novi student, bit će potrebno ispisati ponovo tablicu. Zato trebamo napraviti varijablu statusa u koju će se zapisati da li je napravljen novi unos:
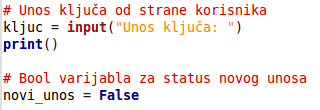
Nakon ovog koraka, potrebno je omogućiti ispis studenta koji se nalazi u tablici odnosno unos studenta ako se uneseni OIB ne nalazi u tablici. Za to koristimo if selekciju koja ispituje da li se uneseni ključ nalazi u tablici, dok se u protivnom traži unos podataka od korisnika.

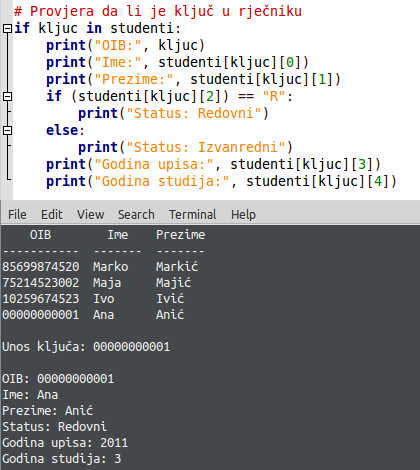
U slučaju unosa OIB-a iz tablice, pod if dio moramo napisati kod koji će nam ispisati samo podatke o datom studentu/studentici. Pripazite kod ispisa elemenata liste. Kao što vidite na slici, prva zagrada predstavlja ključ rječnika, dok je druga indeks liste. Uz to, dodao sam još jednu if selekciju, koja ispituje status studenta i za slovo “R” ispisuje redovni, dok za “I” ispisuje izvanredni. Kod i prikaz rezultata nalazi se na sljedećoj slici:
Ako smo pak unijeli OIB koji se ne nalazi na u tablici, pod else dio moramo napisati kod koji će od korisnika tražiti unos određenih podataka. Ovdje je važno da se podaci upisuju upravo pod ključem koji je unesen kao OIB. Na kraju se naravno ispituje varijabla statusa, a pošto je vrijednost postala True, tablica se ponovno ispisuje, ali sada sadrži i upisanog studenta. Kod i rezultat možete vidjeti na slici ispod:
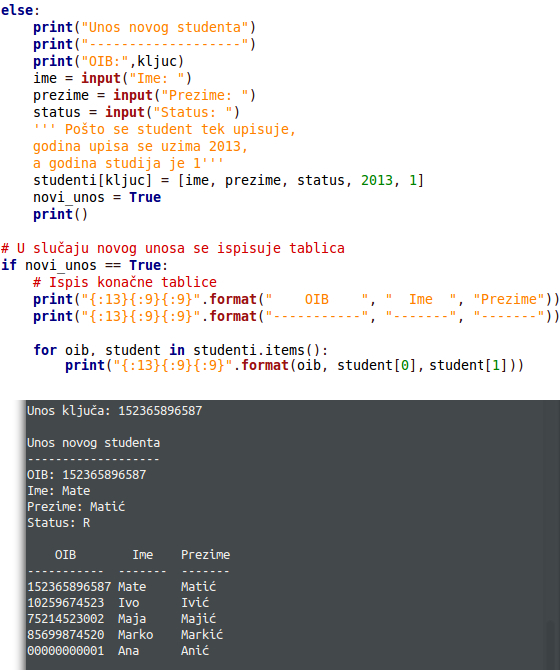
Naravno, kao što sam već napomenuo, ovdje u programu se ne nalazi nikakva kontrola koja kontrolira unos OIB-a, međutim, za one hiperaktivne neka to bude zadatak za domaću zadaću.
Da u potpunosti oblikujemo program, možemo sve (osim rječnika kako bi nove vrijednosti ostale zapisane u njemu) staviti u jednu while iteraciju kako bi se postupak ponovio onoliko puta koliko korisnik želi.
Dio koji je ostao za kraj, a nisam ga prije obrađivao vezan je za skupove. Radi se o tipu podataka koji nema istih elemenata (“duplića”).
Prazan skup definiramo kao:
skup = set()
Ako želimo dodavati elemente u skup, koristimo metodu .add()
skup.add(100)
Na ovaj način smo skupu dodali vrijednost 100. Također, ako neki element želimo maknuti iz skupa, koristimo .remove().
Također, ovdje se nalaze još neke metode za skupove:
.clear()
Briše sve elemente iz skupa.
.discard()
Briše element iz skupa ako se nalazi u njemu (sigurnija varijanta od .remove() jer u slučaju ako se element ne nalazi u skupu je javlja grešku).
.pop()
Iz skupa uzima element i vraća nam njegovu vrijednost (nakon toga se u skupu taj element više ne nalazi).
Često se skupovi rade iz lista, pa se u tom slučaju koristi funkcija set().
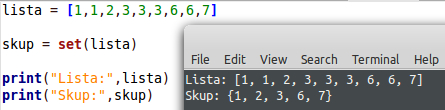
Na ovaj način se iz lista eliminiraju ponavljajući elementi što svakako može imati pozitivne strane, poput lakšeg sortiranja, pretraživanja i “čišćenja” liste od nepotrebnih vrijednosti i zauzimanja prostora.
Ovime smo došli do kraja današnjeg tutoriala! Zadataka ovaj put neće biti, ali si zato ponovite sve što smo dosad radili. Sljedeći put će tema također biti zanimljiva, a radit će se o funkcijama.
Do sljedećeg puta,
Nikola




Ovo postaje sve interesantnije